![]()
A fully updated 2026 DP-700 Exam Dumps exam guide from training expert BraindumpsIT
Provides complete coverage of every objective on exam and exam preparation DP-700
NEW QUESTION # 19
You have an Azure subscription that contains a blob storage account named sa1. Sa1 contains two files named Filelxsv and File2.csv.
You have a Fabric tenant that contains the items shown in the following table.
You need to configure Pipeline1 to perform the following actions:
* At 2 PM each day, process Filel.csv and load the file into flhl.
* At 5 PM each day. process File2.csv and load the file into flhl.
The solution must minimize development effort. What should you use?
- A. a data pipeline schedule
- B. a data pipeline trigger
- C. an activator
- D. a job definition
Answer: A
NEW QUESTION # 20
You have a Fabric workspace that contains a lakehouse named Lakehouse1. Data is ingested into Lakehouse1 as one flat table. The table contains the following columns.
You plan to load the data into a dimensional model and implement a star schema. From the original flat table, you create two tables named FactSales and DimProduct. You will track changes in DimProduct.
You need to prepare the data.
Which three columns should you include in the DimProduct table? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
- A. ProductName
- B. SalesAmount
- C. ProductID
- D. Date
- E. TransactionID
- F. ProductColor
Answer: A,C,F
Explanation:
In a star schema, the DimProduct table serves as a dimension table that contains descriptive attributes about products. It will provide context for the FactSales table, which contains transactional data. The following columns should be included in the DimProduct table:
ProductName: The ProductName is an important descriptive attribute of the product, which is needed for analysis and reporting in a dimensional model.
ProductColor: ProductColor is another descriptive attribute of the product. In a star schema, it makes sense to include attributes like color in the dimension table to help categorize products in the analysis.
ProductID: ProductID is the primary key for the DimProduct table, which will be used to join the FactSales table to the product dimension. It's essential for uniquely identifying each product in the model.
NEW QUESTION # 21
You are building a Fabric notebook named MasterNotebookl in a workspace. MasterNotebookl contains the following code.
You need to ensure that the notebooks are executed in the following sequence:
1. Notebook_03
2. Notebook.Ol
3. Notebook_02
Which two actions should you perform? Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point.
- A. Split the Directed Acyclic Graph (DAG) definition into three separate definitions.
- B. Add dependencies to the execution of Notebook_03.
- C. Add dependencies to the execution of Note boo k_02.
- D. Change the concurrency to 3.
- E. Move the declaration of Notebook_02 to the bottom of the Directed Acyclic Graph (DAG) definition.
- F. Move the declaration of Notebook_03 to the top of the Directed Acyclic Graph (DAG) definition.
Answer: C,F
NEW QUESTION # 22
You have a Fabric workspace that contains a data pipeline named Pipeline! as shown in the exhibit.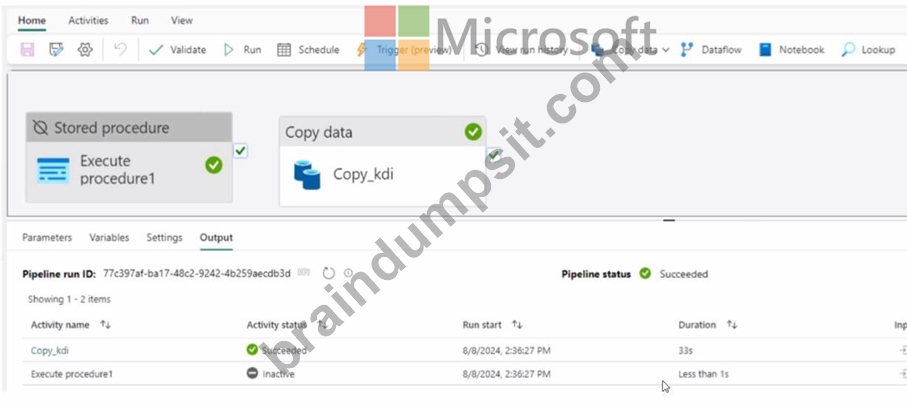
- A. Both activities will run simultaneously.
- B. Copy.kdi will run first, and then Execute procedurel will run.
- C. Execute procedurel will run and Copy_kdi will be skipped.
- D. Copy.kdi will run and Execute procedurel will be skipped.
- E. Execute procedure1 will run first, and then Copy_kdi will run.
- F. Both activities will be skipped.
Answer: A
NEW QUESTION # 23
You have a Fabric workspace that contains a warehouse named Warehouse1.
In Warehouse1, you create a table named DimCustomer by running the following statement.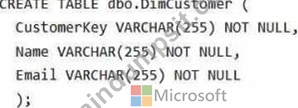
You need to set the Customerkey column as a primary key of the DimCustomer table.
Which three code segments should you run in sequence? To answer, move the appropriate code segments from the list of code segments to the answer area and arrange them in the correct order.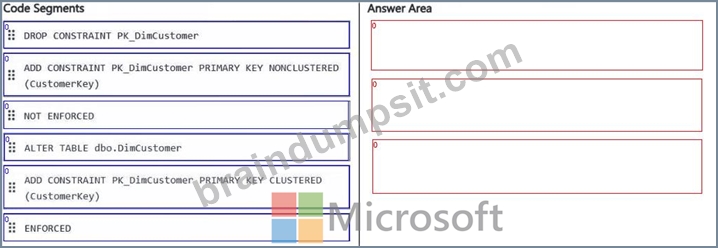
Answer:
Explanation: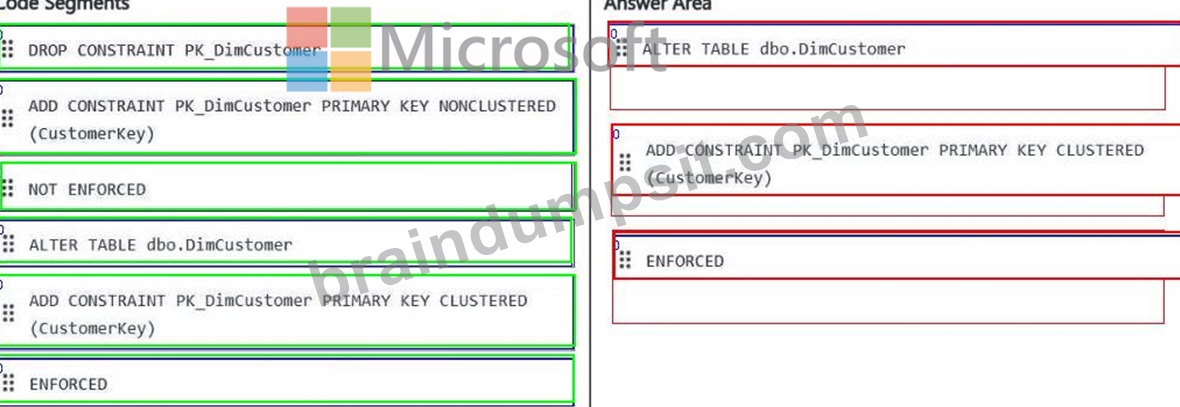
NEW QUESTION # 24
HOTSPOT
You have a Fabric workspace that contains a warehouse named Warehouse1. Warehouse1 contains the following tables and columns.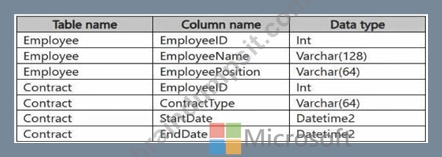
You need to denormalize the tables and include the ContractType and StartDate columns in the Employee table. The solution must meet the following requirements:
Ensure that the StartDate column is of the date data type.
Ensure that all the rows from the Employee table are preserved and include any matching rows from the Contract table.
Ensure that the result set displays the total number of employees per contract type for all the contract types that have more than two employees.
How should you complete the statement? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.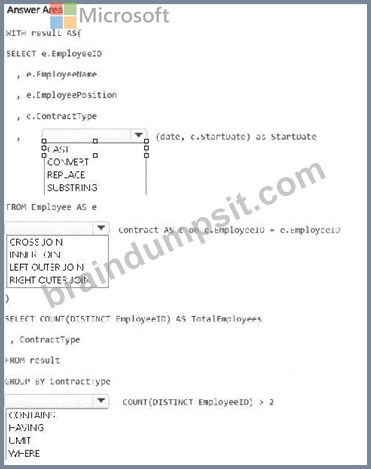
Answer:
Explanation: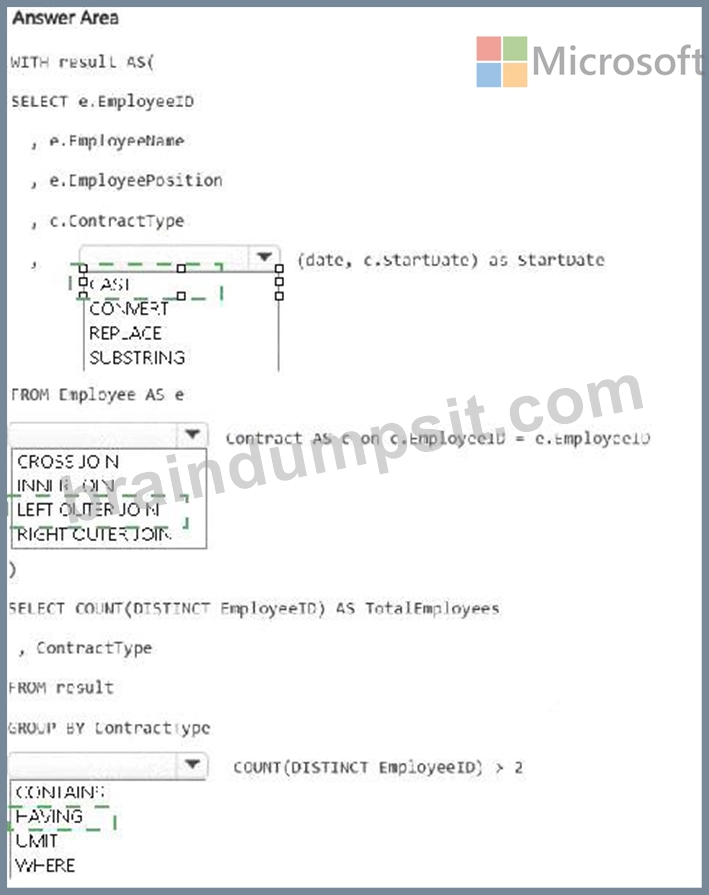
Explanation: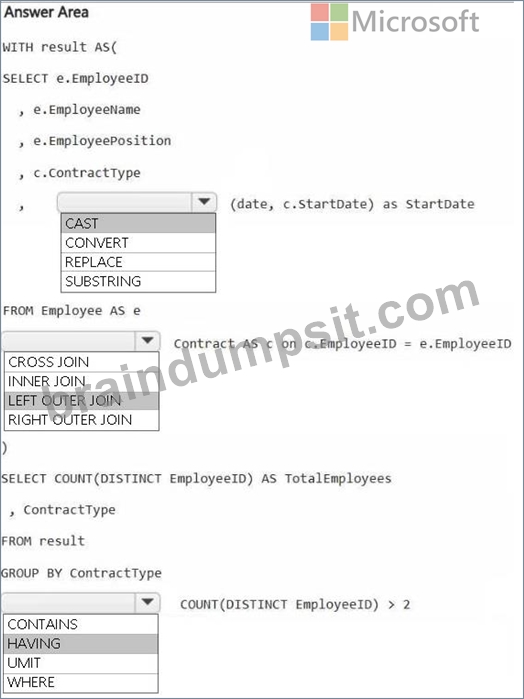
NEW QUESTION # 25
You have three users named User1, User2, and User3.
You have the Fabric workspaces shown in the following table.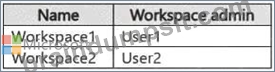
You have a security group named Group1 that contains User1 and User3.
The Fabric admin creates the domains shown in the following table.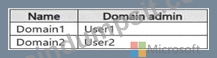
User1 creates a new workspace named Workspace3.
You add Group1 to the default domain of Domain1.
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.
Answer:
Explanation:
Explanation:
NEW QUESTION # 26
You have a table in a Fabric lakehouse that contains the following data.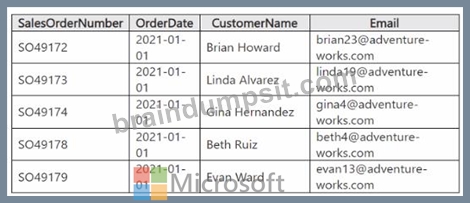
You have a notebook that contains the following code segment.
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.
Answer:
Explanation:
NEW QUESTION # 27
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have a Fabric eventstream that loads data into a table named Bike_Location in a KQL database. The table contains the following columns:
BikepointID
Street
Neighbourhood
No_Bikes
No_Empty_Docks
Timestamp
You need to apply transformation and filter logic to prepare the data for consumption. The solution must return data for a neighbourhood named Sands End when No_Bikes is at least 15. The results must be ordered by No_Bikes in ascending order.
Solution: You use the following code segment:
Does this meet the goal?
- A. no
- B. Yes
Answer: A
Explanation:
This code does not meet the goal because it uses order by, which is not valid in KQL. The correct term in KQL is sort by.
Correct code should look like:
NEW QUESTION # 28
You have an Azure Data Lake Storage Gen2 account named storage1 and an Amazon S3 bucket named storage2.
You have the Delta Parquet files shown in the following table.
You have a Fabric workspace named Workspace1 that has the cache for shortcuts enabled. Workspace1 contains a lakehouse named Lakehouse1. Lakehouse1 has the following shortcuts:
The data from which shortcuts will be retrieved from the cache?
- A. Products. Stores, and Trips
- B. Trips and Stores only
- C. Stores only
- D. Products only
- E. Products and Store only
Answer: E
Explanation:
When the cache for shortcuts is enabled in Fabric, the data retrieval is governed by the caching behavior, which generally retains data for a specific period after it was last accessed. The data from the shortcuts will be retrieved from the cache if the data is stored in locations that support caching. Here's a breakdown based on the data's location:
Products: The ProductFile is stored in Azure Data Lake Storage Gen2 (storage1). Since Azure Data Lake is a supported storage system in Fabric and the file is relatively small (50 MB), this data is most likely cached and can be retrieved from the cache.
Stores: The StoreFile is stored in Amazon S3 (storage2), and even though it is stored in a different cloud provider, Fabric can cache data from Amazon S3 if caching is enabled. This data (25 MB) is likely cached and retrievable.
Trips: The TripsFile is stored in Amazon S3 (storage2) and is significantly larger (2 GB) compared to the other files. While Fabric can cache data from Amazon S3, the larger size of the file (2 GB) may exceed typical cache sizes or retention windows, causing this file to likely be retrieved directly from the source instead of the cache.
NEW QUESTION # 29
You have a Fabric workspace that contains a lakehouse named Lakehouse1.
In an external data source, you have data files that are 500 GB each. A new file is added every day.
You need to ingest the data into Lakehouse1 without applying any transformations. The solution must meet the following requirements Trigger the process when a new file is added.
Provide the highest throughput.
Which type of item should you use to ingest the data?
- A. KQL queryset
- B. Dataflow Gen2
- C. Environment
- D. Data pipeline
Answer: D
Explanation:
To efficiently ingest large data files (500 GB each) into Lakehouse1 with high throughput and trigger the process when a new file is added, a Data pipeline is the most suitable solution. Data pipelines in Fabric are ideal for orchestrating data movement and can be configured to automatically trigger based on file arrivals or other events. This solution meets both requirements: ingesting the data without transformations (since you just need to copy the data) and triggering the process when new files are added.
NEW QUESTION # 30
You have an Azure event hub. Each event contains the following fields:
BikepointID
Street
Neighbourhood
Latitude
Longitude
No_Bikes
No_Empty_Docks
You need to ingest the events. The solution must only retain events that have a Neighbourhood value of Chelsea, and then store the retained events in a Fabric lakehouse.
What should you use?
- A. a streaming dataset
- B. a KQL queryset
- C. an eventstream
- D. Apache Spark Structured Streaming
Answer: C
Explanation:
An eventstream is the best solution for ingesting data from Azure Event Hub into Fabric, while applying filtering logic such as retaining only the events that have a Neighbourhood value of "Chelsea." Eventstreams in Microsoft Fabric are designed for handling real-time data streams and can apply transformation logic directly on incoming events. In this case, the eventstream can filter events based on the Neighbourhood field before storing the retained events in a Fabric lakehouse.
Eventstreams are well-suited for stream processing, such as this case where you need to filter out only specific data (events with a Neighbourhood of "Chelsea") before storing it in the lakehouse.
NEW QUESTION # 31
You have a Fabric workspace that contains a warehouse named DW1. DW1 is loaded by using a notebook named Notebook1.
You need to identify which version of Delta was used when Notebook1 was executed.
What should you use?
- A. Real-Time hub
- B. OneLake data hub
- C. Fabric Monitor
- D. the Microsoft Fabric Capacity Metrics app
- E. the Admin monitoring workspace
Answer: E
Explanation:
To identify the version of Delta used when Notebook1 was executed, you should use the Admin monitoring workspace. The Admin monitoring workspace allows you to track and monitor detailed information about the execution of notebooks and jobs, including the underlying versions of Delta or other technologies used. It provides insights into execution details, including versions and configurations used during job runs, making it the most appropriate choice for identifying the Delta version used during the execution of Notebook1.
NEW QUESTION # 32
You need to recommend a method to populate the POS1 data to the lakehouse medallion layers.
What should you recommend for each layer? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.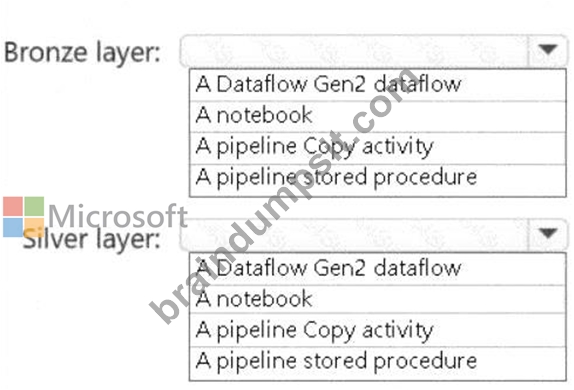
Answer:
Explanation: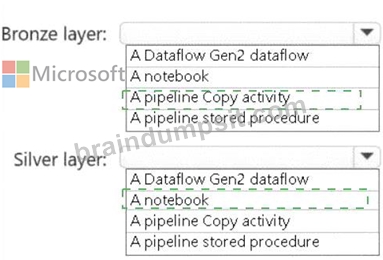
Explanation:
A screenshot of a computer Description automatically generated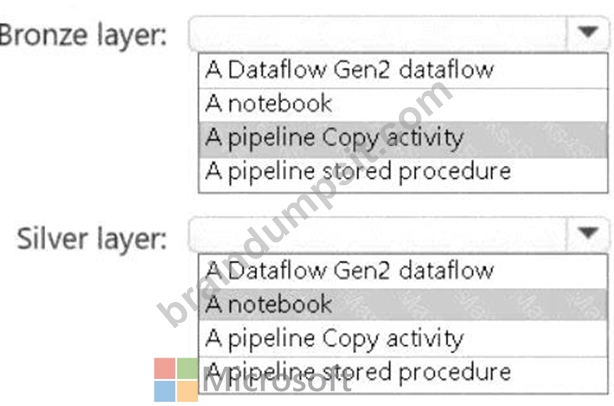
Bronze Layer: A pipeline Copy activity
The bronze layer is used to store raw, unprocessed data. The requirements specify that no transformations should be applied before landing the data in this layer. Using a pipeline Copy activity ensures minimal development effort, built-in connectors, and the ability to ingest the data directly into the Delta format in the bronze layer.
Silver Layer: A notebook
The silver layer involves extensive data cleansing (deduplication, handling missing values, and standardizing capitalization). A notebook provides the flexibility to implement complex transformations and is well-suited for this task.
NEW QUESTION # 33
You have a KQL database that contains a table named Readings.
You need to build a KQL query to compare the Meter-Reading value of each row to the previous row base on the ilmestamp value A sample of the expected output is shown in the following table.

Answer:
Explanation:
Explanation:
NEW QUESTION # 34
You need to create the product dimension.
How should you complete the Apache Spark SQL code? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.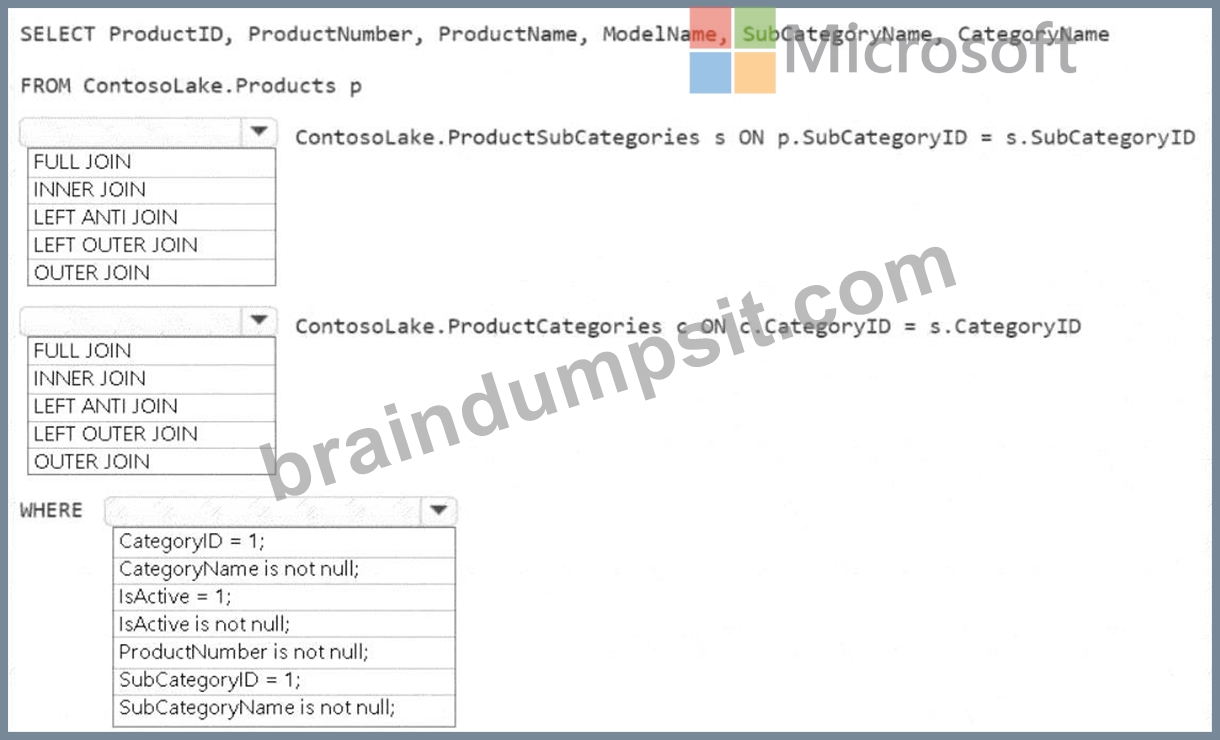
Answer:
Explanation: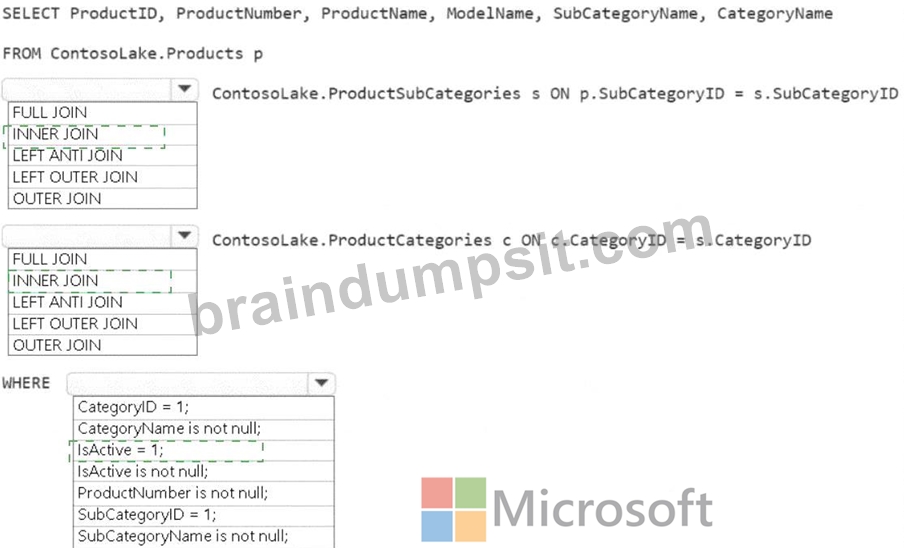
Explanation:
A screenshot of a computer Description automatically generated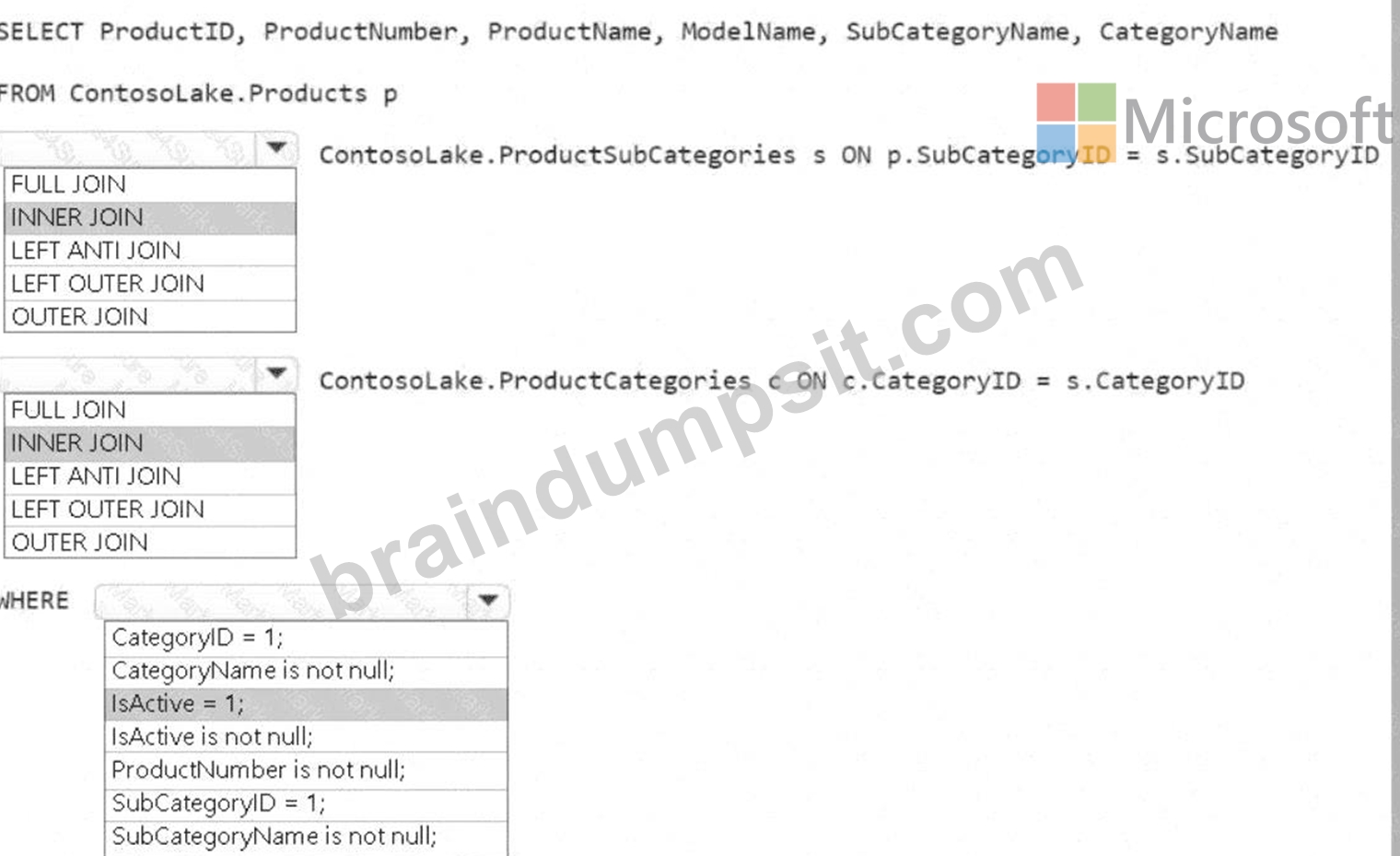
Join between Products and ProductSubCategories:
Use an INNER JOIN.
The goal is to include only products that are assigned to a subcategory. An INNER JOIN ensures that only matching records (i.e., products with a valid subcategory) are included.
Join between ProductSubCategories and ProductCategories:
Use an INNER JOIN.
Similar to the above logic, we want to include only subcategories assigned to a valid product category. An INNER JOIN ensures this condition is met.
WHERE Clause
Condition: IsActive = 1
Only active products (where IsActive equals 1) should be included in the gold layer. This filters out inactive products.
NEW QUESTION # 35
You need to recommend a method to populate the POS1 data to the lakehouse medallion layers.
What should you recommend for each layer? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.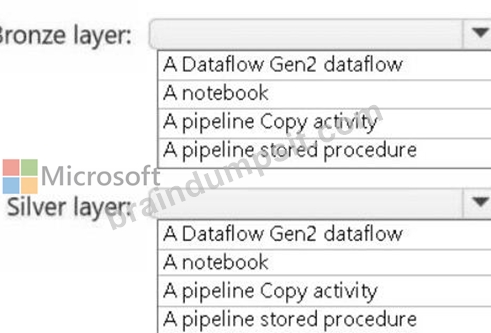
Answer:
Explanation: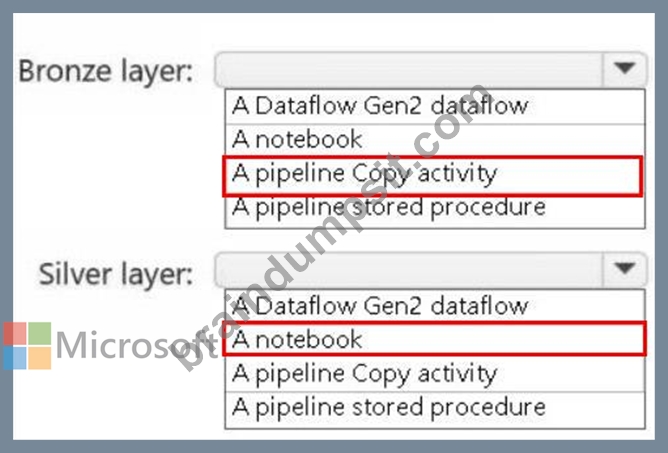
NEW QUESTION # 36
HOTSPOT
You have a Fabric workspace that contains a warehouse named Warehouse1. Warehouse1 contains the following tables and columns.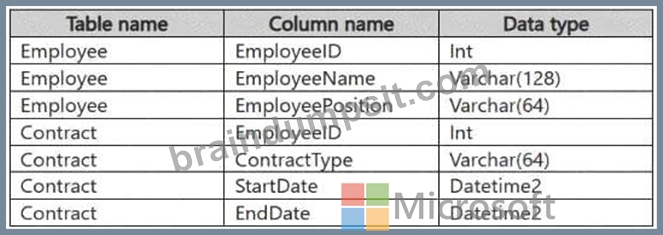
You need to denormalize the tables and include the ContractType and StartDate columns in the Employee table. The solution must meet the following requirements:
Ensure that the StartDate column is of the date data type.
Ensure that all the rows from the Employee table are preserved and include any matching rows from the Contract table.
Ensure that the result set displays the total number of employees per contract type for all the contract types that have more than two employees.
How should you complete the statement? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Answer:
Explanation:
Explanation: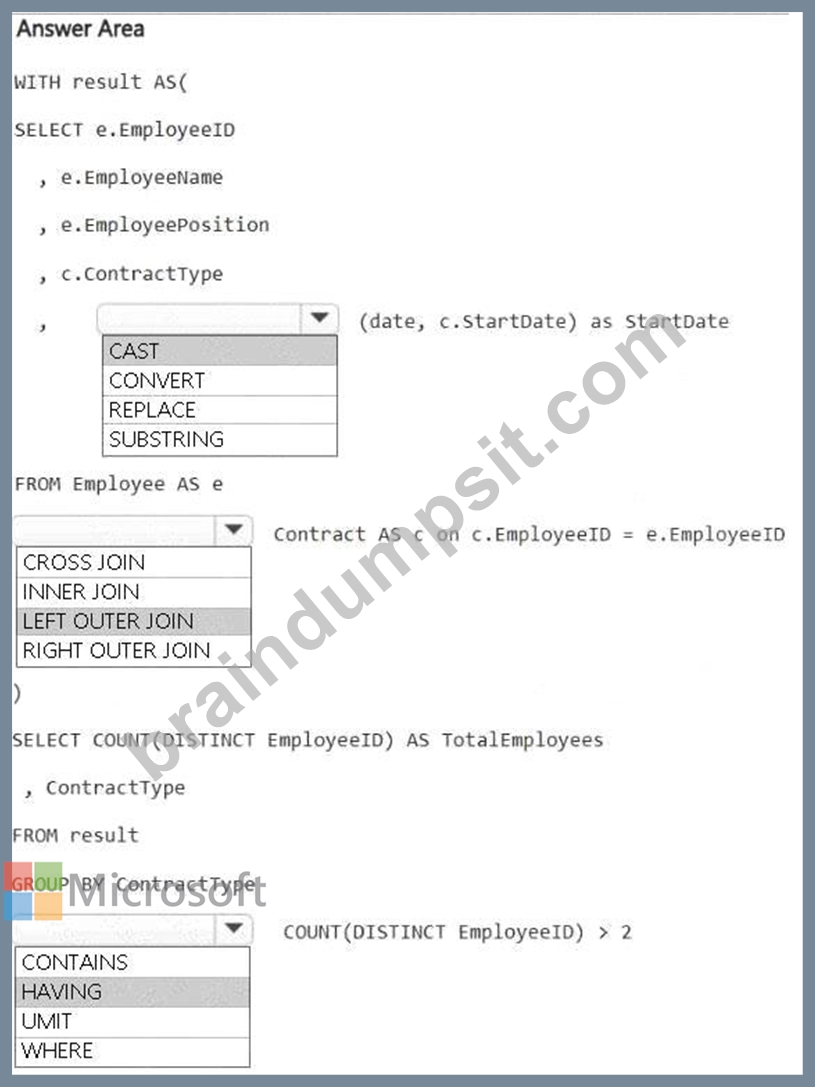
NEW QUESTION # 37
You have a Fabric workspace that contains a warehouse named Warehouse1. Data is loaded daily into Warehouse1 by using data pipelines and stored procedures.
You discover that the daily data load takes longer than expected.
You need to monitor Warehouse1 to identify the names of users that are actively running queries.
Which view should you use?
- A. sys.dm_exec_sessions
- B. sys.dm_exec_connections
- C. queryinsights.frequently_run_queries
- D. sys.dm_exec_requests
- E. queryinsights.long_running_queries
Answer: A
Explanation:
sys.dm_exec_sessions provides real-time information about all active sessions, including the user, session ID, and status of the session. You can filter on session status to see users actively running queries.
NEW QUESTION # 38
You are building a data orchestration pattern by using a Fabric data pipeline named Dynamic Data Copy as shown in the exhibit. (Click the Exhibit tab.)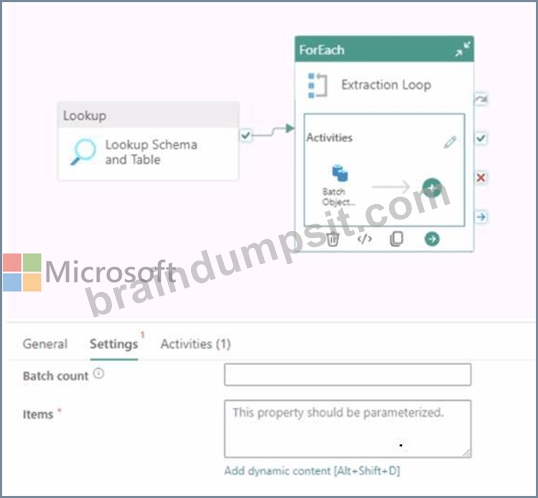
Dynamic Data Copy does NOT use parametrization.
You need to configure the ForEach activity to receive the list of tables to be copied.
How should you complete the pipeline expression? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Answer:
Explanation:
Explanation:
NEW QUESTION # 39
......
Microsoft DP-700 Exam Syllabus Topics:
| Topic | Details |
|---|---|
| Topic 1 |
|
| Topic 2 |
|
| Topic 3 |
|
Tested Material Used To DP-700: https://www.braindumpsit.com/DP-700_real-exam.html
Steps Necessary To Pass The DP-700 Exam: https://drive.google.com/open?id=1QR3H3iFMURL7WlCrsJgp3ulT6z9rm8k7